8.8 KiB
8.8 KiB
deck:: Logseq/coding tip
-
► 이차원 배열(n*m) 생성 #card
id:: 690daa52-9b76-4367-bcf3-386b33637eb0-
arr = [[0]*m for _ in range(n)]
-
-
► lambda(람다) 함수
-
◼︎ 정의 #card
id:: 690daba5-24c2-4cdc-9373-3e1924b96cb7- 파이썬에서 이름이 없는 익명 함수를 만드는데 사용되는 키워드
- def 키워드로 정식으로 정의되는 함수보다 훨씬 간결하게, 간단한 함수를 만들 때 사용됨
-
◼︎ 핵심 개념 #card
id:: 690dae10-920a-4ce0-a098-c9053307f872- 이름이 없다 : 변수에 할당하여 사용할 수는 있지만 함수 자체에는 이름이 없다.
- 일회성 : 주로 다른 함수의 인자로 전달되어 한 번만 사용되고 사라지는 용도로 많이 쓰인다.
- 변수에 할당해서 여러번 사용은 가능하지만 주된 사용법이 아니고 권장되지도 않는다.
- 간결함 : 복잡한 로직이 아닌, 간단한 연산을 수행하는 함수를 빠르게 정의할 수 있다.
- 함수 내부에서 변수를 할당하거나 여러 줄의 복잡한 문장을 사용할 수 없고 오직 하나의 표현식만 허용된다.
-
◼︎ 구문 #card
id:: 690dae7c-8d83-4eed-99d6-40f83ec11494-
lambda 인자1, 인자2, ... : 함수정의 # 인자의 개수가 여러개라면 여러개를 콜론으로 구분해서 쭉 나열한다 # 인자들을 나열한 뒤 콜론으로 구분한 뒤 뒤에 함수를 정의한다. # 변수로 할당하기 add_lambda = lambda x, y : x+y print(add_lambda(1,2)) # 3 # 고차함수에 인자로 전달해서 선언하기 nums = [1,2,3,4,5] evens = list(filter(lambda x: x % 2 == 0, nums)) print(evens) # [2,4]
-
-
-
► 유틸 함수 모음
-
◼︎ 정렬함수 (sort, sorted)
- ◉ sort() vs. sorted() 간단 비교
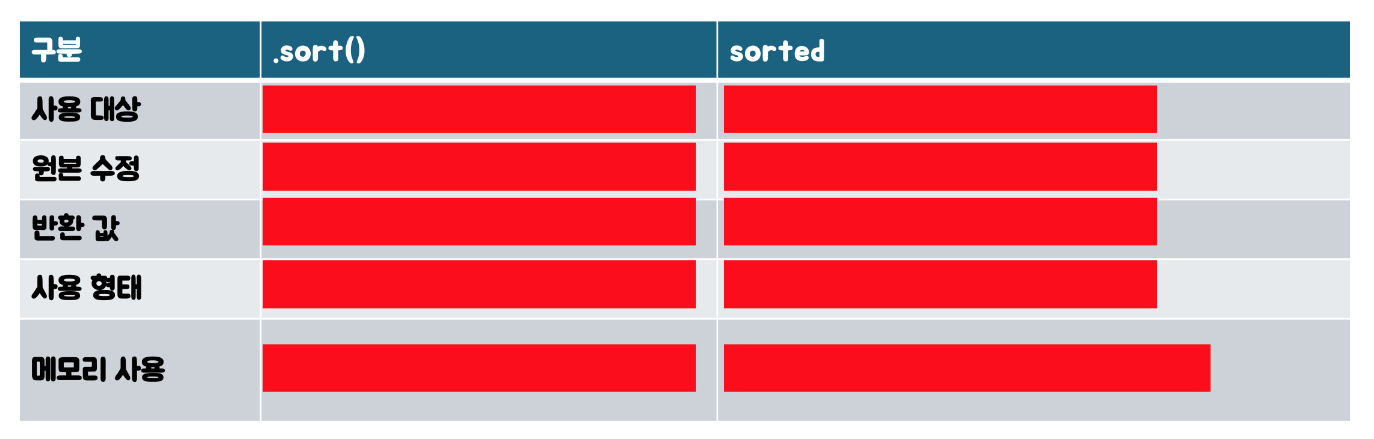 #card
id:: 690db22d-8f77-40b6-8d9a-64fe17f33459
#card
id:: 690db22d-8f77-40b6-8d9a-64fe17f33459
- ◉ 사용 인자
- reverse #card
id:: 690db312-4c67-4fb8-b41a-7c136b2b9f73
- 이 키워드가 True이면 내림차순, False면 오름차순으로 정렬함
- 기본값은 False이고 따라서 따로 지정하지 않으면 기본적으로 오름차순으로 동작함.
-
numbers = [3, 1, 4, 1, 5, 9] numbers_reverse = [3, 1, 4, 1, 5, 9] numbers.sort() # [1,1,3,4,5,9] numbers.sort(reverse=True) # [9,5,4,3,1,1]
- key #card
id:: 690db41f-a507-4ce3-93cb-57f749174d01
- 정렬의 기준을 지정하는 함수를 인자로 받음
- 리스트의 모든 인자에 대해 이 key에 들어간 한수를 한번씩 입력으로 들어간 뒤 이에 대한 비교용 값(proxy value)을 계산해서 반환함.
- 이 반환된 값을 기준으로 오름차순(reverse=True의 경우에는 내림차순)으로 정렬함
- key에 전달되는 함수는 다음과 같다
- len, abs, str 등 내장함수
- lambda를 활용한 복잡한 객체나 특정 조건에 대한 정렬기준을 정의
- def로 정의된 함수로 정렬기준이 복잡하고 여러줄의 코드가 필요할 때 사용
- key에 전달된 함수는 단일 값, 혹은 튜플형태의 반환값을 가져야 한다.
- 튜플형태라면 앞 요소부터 기준에 맞게 정렬하고 같을 경우 그 다음 요소를 비교해서 정렬한다.
- 예제 모음
-
# 공통 예제 데이터 players = [ {'name': 'Son', 'team': 'Tottenham', 'goals': 23, 'assists': 7}, {'name': 'Kane', 'team': 'Tottenham', 'goals': 17, 'assists': 9}, {'name': 'Salah', 'team': 'Liverpool', 'goals': 23, 'assists': 13}, {'name': 'De Bruyne', 'team': 'Man City', 'goals': 15, 'assists': 8}, {'name': 'Mane', 'team': 'Liverpool', 'goals': 16, 'assists': 2}, {'name': 'Jota', 'team': 'Liverpool', 'goals': 15, 'assists': 4}, ]- 이름 기준 사전순 정렬 #card
id:: 690dcc7a-cd85-428a-a734-337df0430ef6
-
players.sort(key=lambda p: p['name'])
-
- 득점(goals) 기준 내림차순 정렬 #card
id:: 690dccf5-9182-401f-84c7-95f9c44d14de
-
players.sort(key=lambda p: -p['goals'])
-
- 공격포인트(goals + assists) 값 기준 내림차순, 같다면 팀 이름 사전순, 팀이 같다면 선수 이름 사전순 #card
id:: 690dcd55-e279-4f3f-a75f-579d0612bfef
-
players.sort(key=lambda p: (-(p['goals'] + p['assists']), p['team'], p['name']))
-
- 이름 기준 사전순 정렬 #card
id:: 690dcc7a-cd85-428a-a734-337df0430ef6
-
- reverse #card
id:: 690db312-4c67-4fb8-b41a-7c136b2b9f73
- ◉ sort() vs. sorted() 간단 비교
-
◼︎ zip()
- 개념
- 여러 개의 {{c1 순회 가능한(iterable) 객체(리스트, 튜플 등)}} 를 인자로 받아, 각 객체의 {{c1 동일한 인덱스}} 에 있는 요소들을 하나로 묶어 {{c1 튜플(tuple)}} 형태로 반환하는 {{c1 이터레이터}}를 생성함. id:: 6958f1f9-40c2-46a0-aaa0-f8bdf3e22298
- 특징
- 인자로 전달된 객체들의 길이가 다를 경우 :-> 가장 짧은 객체의 길이를 기준으로 동작이 멈춤. extra:: 멈춘 이후 묶이지 않은 나머지는 버려짐 id:: 6958f21a-9421-40cf-8fbf-2daff648553a
- 리스트를 반환하는 것이 아닌 {{c1 iterator}} 를 반환함. extra:: 결과를 출력하려면 리스트나, 튜플로 반환결과를 변환해야함. id:: 6958f244-7f9b-4979-bbeb-8872a6cbd5da
- 예시
- extra:: scores의 95는 짝이 맞지 않아서 버려짐
id:: 6958f2f6-84ff-4dfc-a56b-6b4bc671ab8f
위의 코드의 출력 값은? #card extra:: scores의 95는 짝이 맞지 않아서 버려짐 id:: 6958f2f6-84ff-4dfc-a56b-6b4bc671ab8fnames = ['Alice', 'Bob'] scores = [85, 90, 95] for name, score in zip(names, scores): print(f"{name}: {score}")- 출력 결과
- Alice: 85 Bob: 90
- 분석
- zip(names, socres)의 반환 값은 iterator로서 [("Alice", 85). ("Bob", 90)] 로 만들어지고 이것을 name, score 로 순회하기에 각 튜플이 꺼내져서 각 반복마다 name, socre에 대입된다.
- 출력 결과
- 아래의 정의된 행렬의 전치행렬을 zip 함수를 활용해서 구해보면?
id:: 6958f3e6-2719-472d-948e-b0fed572e182
#cardmatrix = [ [1,2,3], [4,5,6], [7,8,9] ]-
transposed = list(zip(*matrix)) # [(1,4,7), (2,5,8), (3,6,9)] 각 행이 튜플 형태로 만들어짐. transposed_list = [list(row) for row in zip(*matrix)] # [[1,4,7], [2,5,8], [3,6,9] 각 행이 리스트 형태로 만들어짐.
-
- extra:: scores의 95는 짝이 맞지 않아서 버려짐
id:: 6958f2f6-84ff-4dfc-a56b-6b4bc671ab8f
- 개념
-
◼︎ enumerate()
- 개념
- 순회 가능한 객체를 입력받아, {{c1 (인덱스, 값) 형태의 튜플}}을 반환하는 이터레이터 생성. id:: 6958f683-facf-4680-bd87-85abcd13e193
- 두번째 인자로서 start 파라미터를 가진다.(필수는 아님)
- 입력하면 인덱스의 시작 값이 start에 넣어준 값이 됨.
- 예시
- 다음 코드의 출력 결과는?
id:: 6958f6ed-8b9d-497e-92b8-a9fc0ad6ccd8
#cardfruits = ['apple', 'banana', 'cherry'] # 인덱스와 값을 동시에 언패킹 for idx, val in enumerate(fruits, start=1): print(f"{idx}번: {val}")- 1번: apple 2번: banana 3번: cherry
- 다음 코드의 출력 결과는?
id:: 6958f6ed-8b9d-497e-92b8-a9fc0ad6ccd8
- 개념
-
-
► 연산자 모음
-
**◼︎ (:=) Walrus Operator (왈러스 연산자)(바다코끼리 연산자) **
- ◉ 개념
- 기호 : := (바다코끼리의 송곳니를 닮았다고 해서 이렇게 명명됨)
- 정식명칭 : {{cloze 대입표현식(Assignment Expression)}} id:: 69469c23-9a52-4782-a564-be290348f315
- 도입버전 : python 3.8+
- 기능 : 표현식(Expression) 내부에서 변수에 값을 할당하는 동시에 그 값을 반환한다. 즉, “할당”과 “사용”을 한 번에 할 수 있게 해준다.
- ◉ 사용예시
- while 루프
id:: 69469d39-78b9-417c-8dfc-50dfcec28890
다음 코드를 왈러스 연산자를 활용해서 리팩토링 하시오.
#carddata = input() while data != "quit": process(data) data = input()-
while (data := input()) != "quit" : process(data)
-
- while 루프
id:: 69469d39-78b9-417c-8dfc-50dfcec28890
다음 코드를 왈러스 연산자를 활용해서 리팩토링 하시오.
- 리스트 컴프리헨션 효율화
id:: 69469e32-e505-45cf-a9c6-43337bef73c5
다음 코드에서 함수 f(x)가 두번 호출되는 비효율이 발생함. 이를 왈러스 연산자로 효율화 하면?
#cardresults = [f(x) for x in data if f(x) > 0]-
results = [y for x in data if (y := f(x)) > 0]
-
- ◉ 개념
-